Sponge Theory - Scalable Models Inferences
SMI (Scalable Models Inferences)
SMI is an advanced solution for scalable model inferences, designed to optimize performance and efficiency across various application domains. Our modular and scalable architecture enables handling complex tasks by leveraging specialized GPU nodes and interconnected services. This architecture can be deployed locally, ensuring the security of confidential data and allowing local processing without sending data to external services.
SMI Architecture
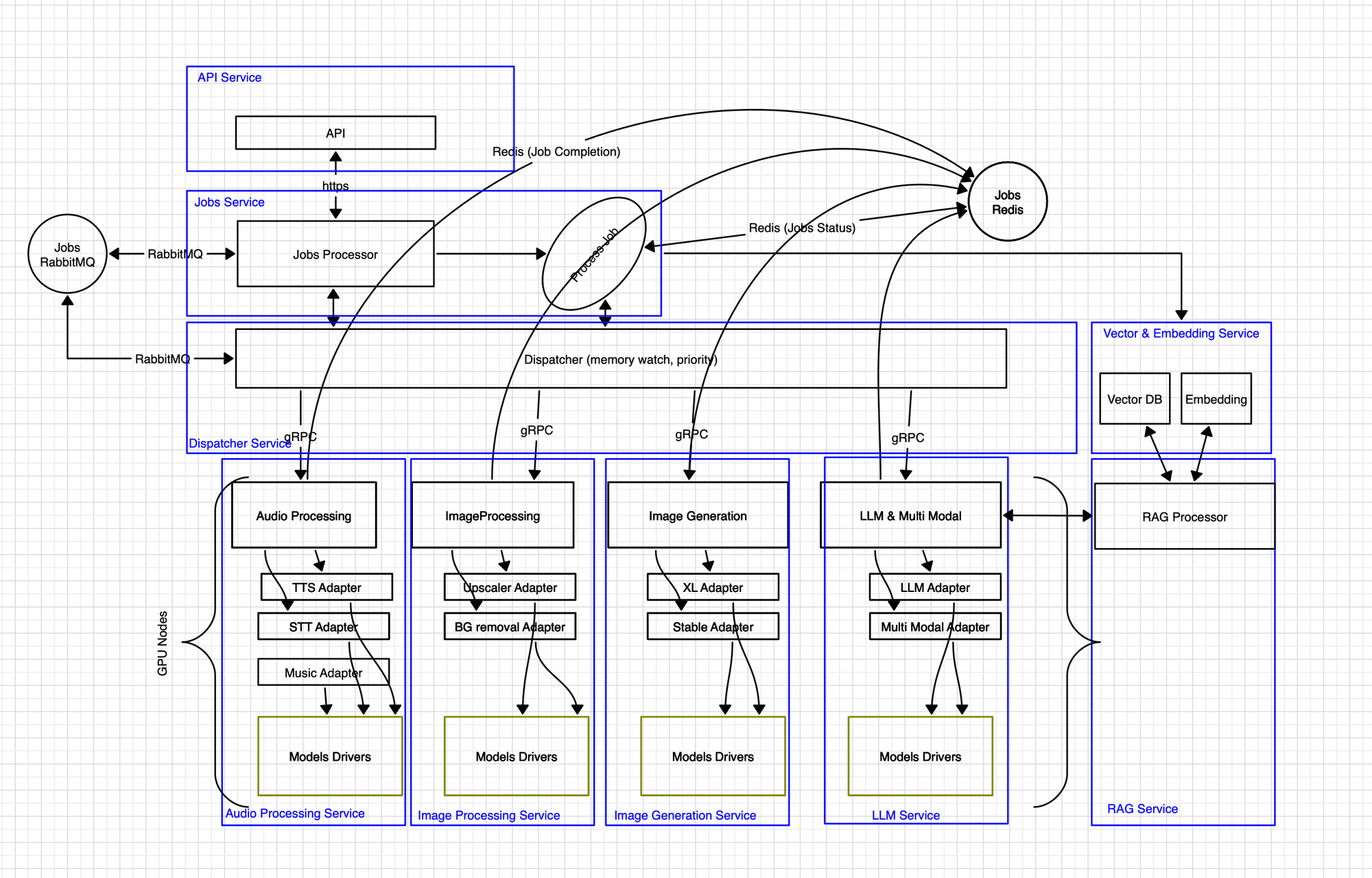
API Service
- A secure interface for task submission and result retrieval via HTTPS.
Jobs Service
- Jobs Processor: Manages the distribution of tasks received through RabbitMQ.
- Dispatcher Service: Oversees the distribution of tasks based on available memory and priorities, using gRPC for communication.
Processing Services
- Audio Processing Service
- Adapters: TTS, STT, Music
- Model Drivers: Execution of specialized models
- Image Processing Service
- Adapters: Upscaler, BG removal
- Model Drivers: Execution of specialized models
- Image Generation Service
- Adapters: XL, Stable
- Model Drivers: Execution of specialized models
- LLM & Multi Modal Service
- Adapters: LLM, Multi Modal
- Model Drivers: Execution of specialized models
Vector & Embedding Service
- Manages data vectorization and embedding to optimize queries and information retrieval.
RAG Service (Retrieval-Augmented Generation)
- RAG Processor: Integrates vectors and embeddings to enhance relevant content generation.
How It Works
- Task Submission
- Tasks are submitted via the API and queued in RabbitMQ.
- Task Processing
- The Jobs Processor retrieves tasks and forwards them to the Dispatcher Service.
- The Dispatcher, based on memory and priorities, sends tasks to the appropriate processing services via gRPC.
- Execution on GPU Nodes
- Each processing service (Audio, Image Processing, Image Generation, LLM & Multi Modal) uses GPU nodes to execute specific models via their adapters and drivers.
- Vectorization and Embedding
- The Vector & Embedding Service handles data transformation for improved query and inference performance.
- Retrieval and Generation
- The RAG Service enhances response generation by integrating vectorized and embedded data.
Benefits
- Scalability: Capable of handling high volumes of requests through a modular and extensible architecture.
- Flexibility: Easily adapts to different types of models and tasks through specific adapters.
- Performance: Optimizes processing and inference times by utilizing specialized GPU nodes.
- Data Security: Local deployment ensures the security of confidential data, allowing processing without the need to send data to external services.
More Infos ? Contact US !


Comments ()