How to use Dolphin-Mixtral uncensored model on you Mac Silicon
This tutorial will show you how to run
This tutorial will show you how to run
TheBloke/dolphin-2.5-mixtral-8x7b-GGUF
on you Mac Silicon.
This model runs with a very good level of performance on a Mac Mx, and it's uncensored 😅
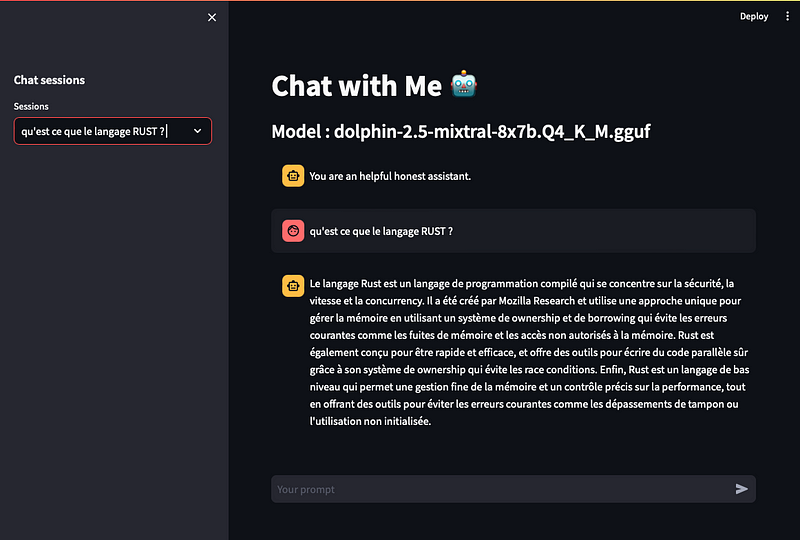
I provide a simple chat interface and its code to converse with the model as well :
I’m using for this tutorial a MacBook Pro M3 Max with 64Go of memory, according the model card, 32Go should me enough.
Installing the dependency
This tutorial rely on lama.cpp, and its python bindings llama-cpp-python
From their installation guide, follow these steps, some have been modified by me, follow them carefully and watch any error messages.
Make sure you have xcode installed… at least the command line parts
- check the path of your xcode install
xcode-select -p
- xcode installed should returns
/Applications/Xcode-beta.app/Contents/Developer
- if xcode is missing then install it… it takes ages;
xcode-select — install
Install the conda version for MacOS that supports Metal GPU
wget https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
bash Miniforge3-MacOSX-arm64.sh
Restart your terminal !
Make a conda environment
conda create -n llama python=3.9.16
conda activate llama
Install the LATEST llama-cpp-python…which happily supports MacOS Metal GPU as of version 0.1.62
(you needed xcode installed in order pip to build/compile the C++ code)
pip uninstall llama-cpp-python -y
CMAKE_ARGS=”-DLLAMA_METAL=on” pip install -U llama-cpp-python — no-cache-dir
pip install streamlit
pip install uuid
- you should now have llama-cpp-python v0.1.62 or higher installed
llama-cpp-python 0.1.68
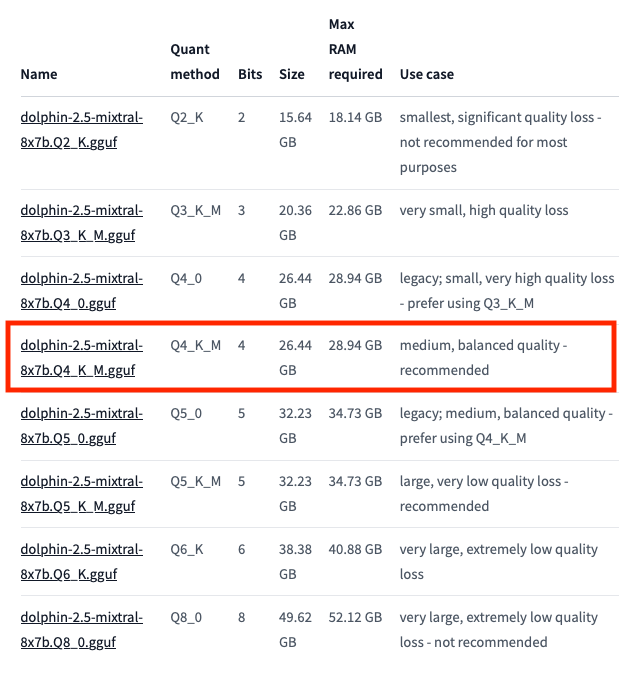
Download a v3 gguf v2 model — ggufv2 — file name ends with Q4_0.gguf — indicating it is 4bit quantized, with quantisation method 0
Please follow the following link :
the model is 26.4Gb, make sure you have enough space available.
Download my chat GUI example from my GITHUB
Create the “models” directory, and copy the model file in it.
The code is quite simple and mimic a simplistic chat interface with chat sessions saving. It use streamlit for the GUI:
import streamlit as st
import os
from llama_cpp import Llama
import uuid
MODEL = "dolphin-2.5-mixtral-8x7b.Q4_K_M.gguf"
MODEL_PATH = "./models"
SESSIONS_PATH = "./sessions"
MODEL_PARAMS = f"{MODEL}.params"
def save_session():
if not os.path.exists(SESSIONS_PATH):
os.makedirs(SESSIONS_PATH)
(sessionTitles, sessionsList) = list_sessions()
sessionUuid = f"{uuid.uuid4()}"
sessionFile = f"{MODEL}.${sessionUuid}.session"
sessionFile = os.path.join(SESSIONS_PATH, sessionFile)
for s in sessionsList:
if s["title"] == st.session_state.messages[1]["content"]:
sessionFile = os.path.join(SESSIONS_PATH, f"{s['file']}")
break
with open(sessionFile, "w") as f:
f.write(str(st.session_state.messages))
def import_session(session: str):
if not os.path.exists(SESSIONS_PATH):
os.makedirs(SESSIONS_PATH)
if os.path.exists(os.path.join(SESSIONS_PATH, f"{session}")):
with open(os.path.join(SESSIONS_PATH, f"{session}"), "r") as f:
content = eval(f.read())
return content
return None
def load_session(session: str):
if not os.path.exists(SESSIONS_PATH):
os.makedirs(SESSIONS_PATH)
if os.path.exists(os.path.join(SESSIONS_PATH, f"{session}")):
with open(os.path.join(SESSIONS_PATH, f"{session}"), "r") as f:
return eval(f.read())
return None
def list_sessions():
if not os.path.exists(SESSIONS_PATH):
os.makedirs(SESSIONS_PATH)
sessionsList = []
sessionTitles = []
for f in os.listdir(SESSIONS_PATH):
if f.endswith(".session"):
session = load_session(f)
if session is not None:
sessionTitle = session[1]["content"]
sessionFile = f
sessionsList.append({
"title": sessionTitle,
"file": sessionFile,
})
sessionTitles.append(sessionTitle)
return (sessionTitles, sessionsList)
llm = Llama(os.path.join(MODEL_PATH, MODEL),
# The max sequence length to use - note that longer sequence lengths require much more resources
verbose=False, n_ctx=32768,
# The number of CPU threads to use, tailor to your system and the resulting performance
n_threads=8,
# The number of layers to offload to GPU, if you have GPU acceleration available
n_gpu_layers=35,
)
st.title("Chat with Me 🤖")
st.subheader(f"Model : {MODEL}")
with st.sidebar:
st.subheader("Chat sessions")
session = st.selectbox('Sessions', ["New Chat"] + list_sessions()[0], index=0, key=f"select chat session to load")
if session == "New Chat":
st.session_state.messages = [
{"role": "system", "content": "You are an helpful honest assistant."}]
else:
for s in list_sessions()[1]:
if s["title"] == session:
messages = import_session(s["file"])
st.session_state.update({"messages": messages})
if "messages" not in st.session_state:
st.session_state.messages = [
{"role": "system", "content": "You are an helpful honest assistant."}]
for message in st.session_state["messages"]:
role = message["role"]
if message["role"] == "system":
role = "assistant"
with st.chat_message(role):
st.markdown(message["content"])
# user input
if user_prompt := st.chat_input("Your prompt"):
st.session_state.messages.append({"role": "user", "content": user_prompt})
with st.chat_message("user"):
st.markdown(user_prompt)
# generate responses
with st.chat_message("assistant"):
message_placeholder = st.text("Thinking...")
full_response = ""
for response in llm.create_chat_completion(
messages = [
{"role": m["role"], "content": m["content"]}
for m in st.session_state.messages
],
stream=True,
max_tokens=4000,
temperature=0.7,
repeat_penalty=1.1,
):
if "content" in response["choices"][0]["delta"]:
full_response += response["choices"][0]["delta"]["content"]
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.messages.append({"role": "assistant", "content": full_response})
save_session()Running the interface on you Mac
If you follow the steps above, you should be able to run the interface like this :
streamlit run chat.py
This is it ! you should be able to engage conversation with the Dolphin-Mixtral model, one of the best actually, with a very good level of performance and remember its uncensored !
If you find this article useful, I would appreciate some claps on it !
Many thanks, and happy reading.

Comments ()